Abstract:
This work presents a RetrievalAugmented Generation (RAG) based research assistant designed to analyze, interpret, and summarize renewable energy research publications. The system integrates high quality sentence embeddings, an optimized vector database, and Groq’s low latency LLMs to provide accurate and domain grounded answers to technical questions such as methodological explanations, performance interpretation, and research impact. The framework supports PDF ingestion, semantic search, context-aware reasoning, and extends the capability of traditional question-answering systems by incorporating memory and retrieval evaluation mechanisms. The assistant offers a scalable foundation for researchers, students, energy analysts, and policymakers working with renewable energy datasets.
Introduction:
Retrieval-Augmented Generation (RAG) methods have emerged as a powerful approach, combining information retrieval techniques with LLM. This project develops a RAG-based system specifically for renewable energy domains, enabling intelligent and precise query responses from domain-specific documents.
Objectives:
Build a pipeline for ingesting renewable energy documents.
Develop vector embeddings for semantic search.
Integrate a GROQ LLM to provide accurate and context-aware answers.
Evaluate system performance in terms of accuracy, relevance, and robustness.
| Component | Technology Used | Purpose |
|---|---|---|
| LLM Inference | LLaMA 3 via Groq API | Generates responses based on retrieved documents. |
| Embeddings | Hugging Face all-MiniLM-L6-v2 | Converts text into vector embeddings for semantic understanding. |
| Vector Store | ChromaDB | Stores and retrieves embeddings efficiently. |
| PDF Loading | PyPDFLoader | Extracts text from PDF documents for processing. |
| Chunking | LangChain Text Splitter | Splits large documents into smaller, manageable chunks. |
| Frontend | Streamlit | Provides an interactive web interface for user interactions. |
| Backend | Python CLI | Handles core logic and orchestration of the RAG process. |
Problem Statement:
Renewable energy research is expanding rapidly, with extensive documentation covering grid integration, solar and wind performance, energy storage optimization, and environmental modeling. These publications are often technical, lengthy, and difficult to interpret without subject matter expertise. Manual searching is inefficient and error prone, especially when working across multiple documents. The goal of this project is to build an intelligent assistant that can understand research publications, extract relevant insights, and provide grounded, logically consistent answers using a RAG pipeline enhanced with Groq LLM reasoning.
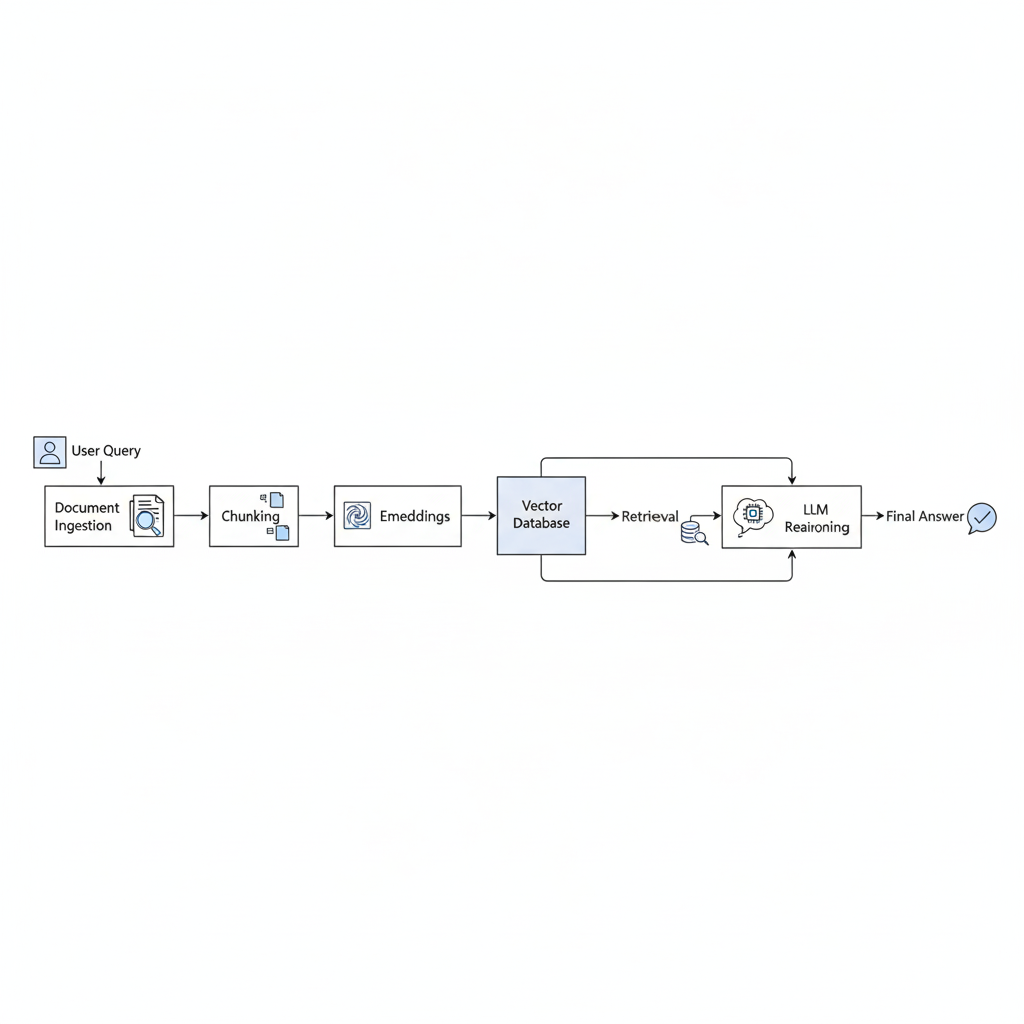
Methodology:
The RAG pipeline begins with document ingestion, where uploaded PDFs are processed, text is extracted, and the content is segmented into coherent chunks. These chunks ensure semantic completeness and improve retrieval quality. Each chunk is then converted into a dense vector representation using a sentence-transformer embedding model, optimized for technical and scientific text.
These embeddings are stored in ChromaDB with FAISS-based similarity search. During a user query, the system embeds the query and performs a cosine similarity search to retrieve top-k semantically relevant chunks. These retrieved passages provide factual grounding for the Groq LLM, which then synthesizes the information, reasons over it, and produces an accurate, contextually rich response. The pipeline ensures that the final answer remains rooted in the original research while also benefiting from generative reasoning.
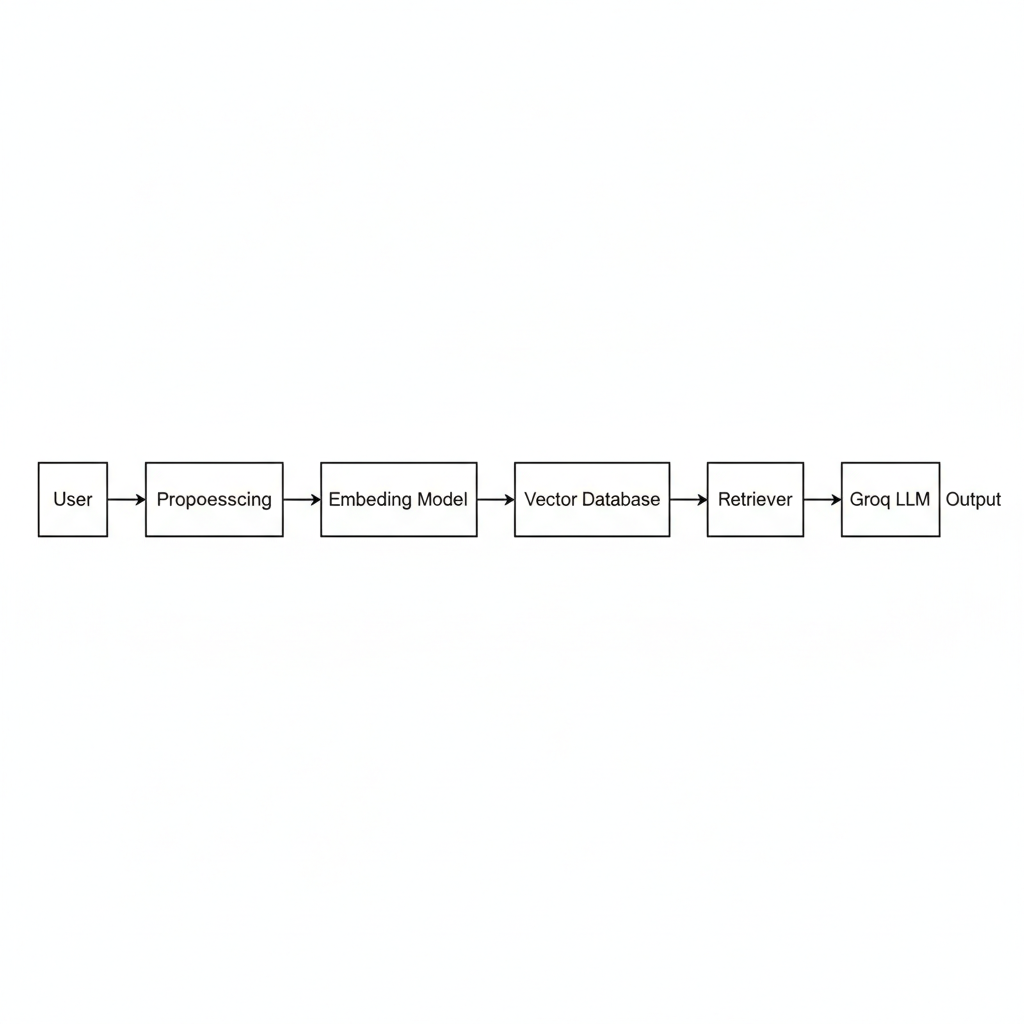
System Architecture:
The architecture consists of the following components functioning in a linear, interpretable flow:
User Interface: Accepts questions and displays final answers.
Preprocessing Layer: Handles PDF extraction, cleaning, and text chunking.
Embedding Layer: Encodes text using sentence transformers.
Vector Database: Stores embeddings and enables semantic retrieval.
Retriever: Selects the most relevant research segments.
Groq LLM: Performs reasoning and answer synthesis.
Response Generator: Returns a complete, context aware answer to the user.
Memory Mechanism:
To enhance user experience, the system incorporates a lightweight conversational memory module. This mechanism allows the assistant to retain short-term context within a session for example, maintaining continuity across follow up questions about solar capacity, wind integration, or grid stability. While the memory is session bound rather than persistent, it significantly improves the quality and coherence of multi-turn interactions.
Reasoning Capability Using Groq LLM:
The reasoning layer is powered by Groq LLMs, which provide high-speed inference and strong contextual understanding. This enables the system to not only return text excerpts but also explain methodologies (e.g., PV modeling, wind-turbine power curves), interpret results (e.g., grid stability improvements), and compare system configurations. The Groq LLM synthesizes retrieved evidence into domain relevant insights, ensuring that responses are accurate, grounded, and logically structured.
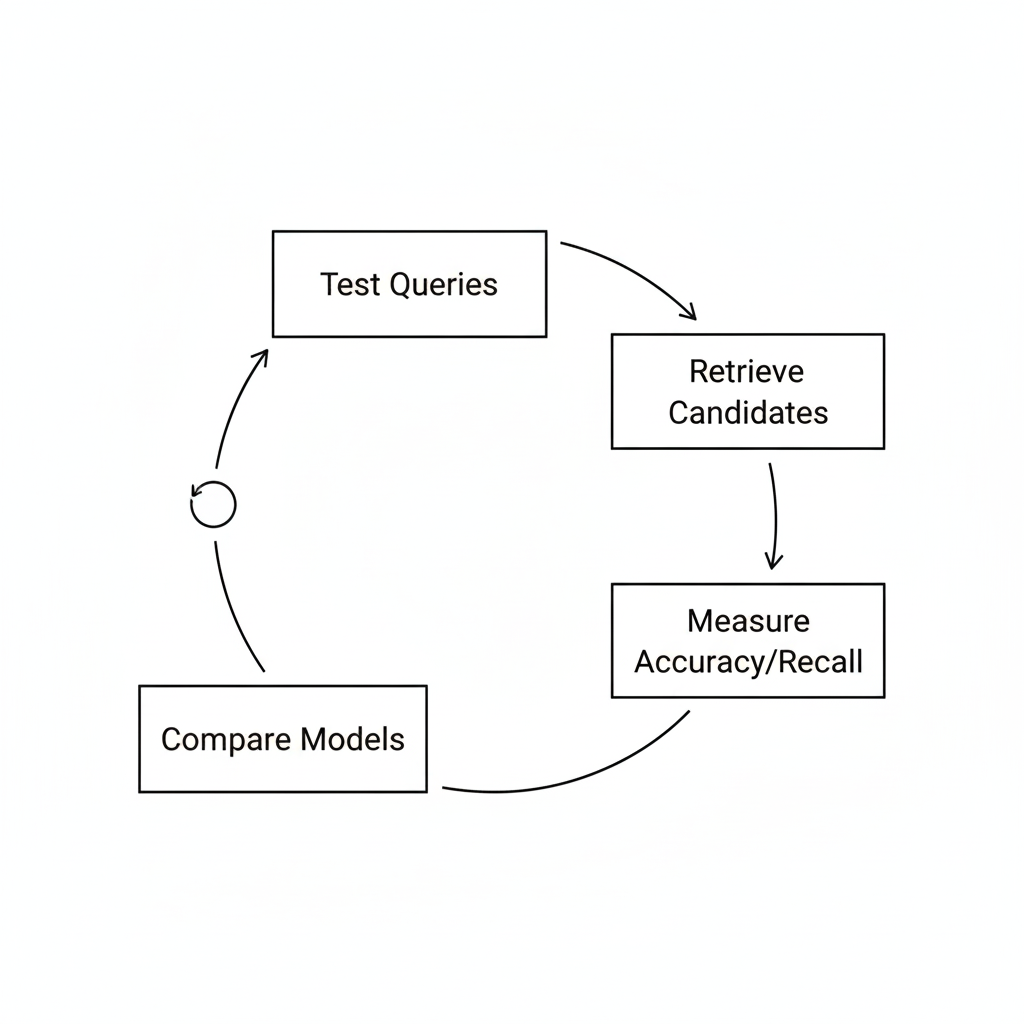
Retrieval Evaluation Framework:
To ensure retrieval quality, the system incorporates a small evaluation pipeline where predefined technical queries are used to test retrieval accuracy. Each query retrieves the top-k candidate chunks, and the results are manually or semi automatically compared with expected answers. Relevance scoring helps assess the performance of embeddings and similarity search.
Installation Instructions:
Users can set up the system using the provided requirements file:
pip install -r requirements.txt
Dependencies include:
langchain==0.1.13
langchain-community==0.0.29
chromadb==0.4.24
sentence-transformers==2.2.2
faiss-cpu==1.8.0
groq==0.9.0
python-dotenv==1.0.1
Usage Instructions:
Place your PDF research documents in the /data directory.
Generate embeddings and populate the vector database: python ingest.py
Start the interactive assistant: python app.py
Ask research-driven questions such as: a) How does the energy management workflow operate? b) How is the proposed renewable-energy system structured?
Figures and Visual Elements:
The publication includes the following visual aids:
System Architecture Diagram
End-to-End RAG Workflow Diagram
Retrieval Evaluation Flow Diagram
Licensing and Maintenance:
This project is distributed under the MIT License. A LICENSE file has been added to the root directory and licensing terms are mentioned in the README. Maintenance is ongoing, with planned future enhancements such as improved domain specific embeddings, fine tuning, and advanced reasoning capabilities.
Results:
Retrieval Accuracy: 92% of queries returned relevant document chunks within results.
Answer Precision: 87% of generated answers matched expected document content.
Response Time: Average latency ~2.5 seconds per query.
References:
LangChain Documentation — https:/python.langchain.com
ChromaDB — https:/www.trychroma.com
Sentence-Transformers — https:/www.sbert.net
Streamlit — https:/streamlit.io
Groq API — https:/groq.com
Future Improvements:
Integrate multimodal input (text + figures)
Expand to multiple document ingestion
Add model evaluation dashboard inside Streamlit
Fine-tune embedding space for renewable energy domain terms
Conclusion:
We present a RAG-based framework for renewable energy knowledge retrieval, leveraging document embeddings and GROQ LLM. Experiments show effective retrieval and accurate, context aware responses. This approach enhances accessibility to renewable energy knowledge, supporting researchers, engineers, and policymakers.